
Introduction:
As we discussed in a previous post, Application Programming Interfaces (API)s allow resource-owners to control access to their sensitive data or proprietary tools. Plumber, the R package, is equipped with the necessary functions to help control access to the resources hosted by the APIs it powers.
So, in this post, we will:
- discuss the relevance to HTA,
- discuss the API we will play with,
- host the API locally,
- introduce plumber filter,
- write a few filters to control access, and
- demonstrate interacting with a controlled API.
Relevance, prerequisites and difficulty:
Relevance:
We have started discussing APIs and their relevance in a previous post. Nonetheless, we reiterate that APIs allow us to separate decision-analytic models from the data that populate or inform such models. This feature is essential because it enables developers to disseminate their models, contributing to open science and allowing reviewers and peers to revise or use them.
Difficulty:
We rank this tutorial as intermediate owing to the background knowledge and skills it builds upon and the technical bits it covers.
Prerequisites:
We expect those who intend to follow along to understand the basics of plumber-powered APIs (please see here for a quick recap). We also utilise some of the commands required to interact with APIs programmatically (we covered these here).
Moreover, we need the software:
- R,
- RStudio, and
- Docker.
We utilise both RStudio and Visual Studio Code (VS code) Integrated Development Environments (IDE)s in this tutorial, with VS code allowing us to spin up the required docker container(s) while making changes to the APIs code. Therefore, Having VS code in our systems would ease the process of following along but is unnecessary for this tutorial.
The files containing the code we demonstrate below are hosted here. Once we have cloned this repository, using the git clone command, we need to open PowerShell from within the “posts” folder to ensure that the commands demonstrated below work on our systems. Finally, we recorded the screenshots and videos below using the files hosted in said repository.
The API:
Smith et al. (2022)1 covered the usefulness of APIs in general and their applications in the Health Technology Appraisal (HTA) domain. Also, the authors provide an example API that:
- controls access to some fictitious data, allowing authorised users to pass their decision-analytic model code to the API hosting infrastructure,
- processes the code, and
- responds with the outputs of the analysis.
We use the code provided by Smith et al. (2022) in this tutorial. We advise those interested in learning more about the API to consult the paper. The files we are hosting in the GitHub repository here contain Smith et al. (2022) API files with the amendments we demonstrate below.
Hosting the API:
To host the Smith et al. (2022) API, we will see the same docker image we built in the “Interacting with a plumber-powered API programmatically” tutorial. In doing so, we get to observe the feedback from the API, just as we saw in said post.
Filtering requests:
Introducing plumber filters:
Plumber filters are API functions that constitute part of or a pipeline for handling incoming requests2. API filters, or at least plumber filters, differ from endpoints in that a request can pass through several filters but only one endpoint before the API generates a response. However, some endpoints can be programmed to bypass one or more filters.
Defining our first filter:
Our first plumber filter is a slightly amended version of the logger filter described here. This filter is less of a filter but more of a logger. This statement might not be clear, but let us explain it by discussing the filter definition below.
1
2
3
4
5
6
7
8
9
10
#* Log some information about the incoming request
#* @filter logger
function(req){
cat(
"Time: ", as.character(Sys.time()), "\n",
"HTTP verb: ", req$REQUEST_METHOD, "\n",
"Endpoint: ", req$PATH_INFO, "\n",
"Request issuer: ", req$HTTP_USER_AGENT, "@", req$REMOTE_ADDR, "\n")
plumber::forward()
}
In the code chunk above we:
- employed the same annotations or decorations
#*we used before to define the API and its endpoints, - used the flag
@filterfollowed byloggerto declare a plumber filter with the namelogger, and - defined the function that serves the API filter. This function prints information to the R console and the container’s terminal.
As we can see from the code chunk above, the printed information is part of the request object. To learn more about a request object’s contents, please check here. That said, the logger filter prints the:
- REQUEST_METHOD: which is the HTTP verb, for example (
GET,POST, etc), - PATH_INFO: which is the name of the endpoint to which plumber will pass the request,
- HTTP_USER_AGENT: which is the name of the browser and the operating system sending the request, and
- REMOTE_ADDR: which is the internet protocol (IP) address of the system sending the request. The filter function then concludes with the
plumber::forwardfunction, which passes control to the pipeline’s next handler (other filter or intended endpoint).
Now let us build the docker image and spin a container to test the logger filter. The commands below are almost identical to the ones we used and explained in the Interacting with a plumber-powered API programmatically post.
1
2
3
4
# Build the docker image using the dockerfile mentioned earlier:
docker build --tag living_hta:2.0 --file .\controlling-and-monitoring-access-to-plumber-powered-APIs\Dockerfile .\controlling-and-monitoring-access-to-plumber-powered-APIs
# Spin a container up in the foreground (keep access to the container's inputs and outputs):
docker run -p 8080:8000 -it --rm --name living_hta_api living_hta:2.0
The screen recording below displays building the docker image and running a container instance. It also shows how the container reacts, including the information printed by the logger filter.
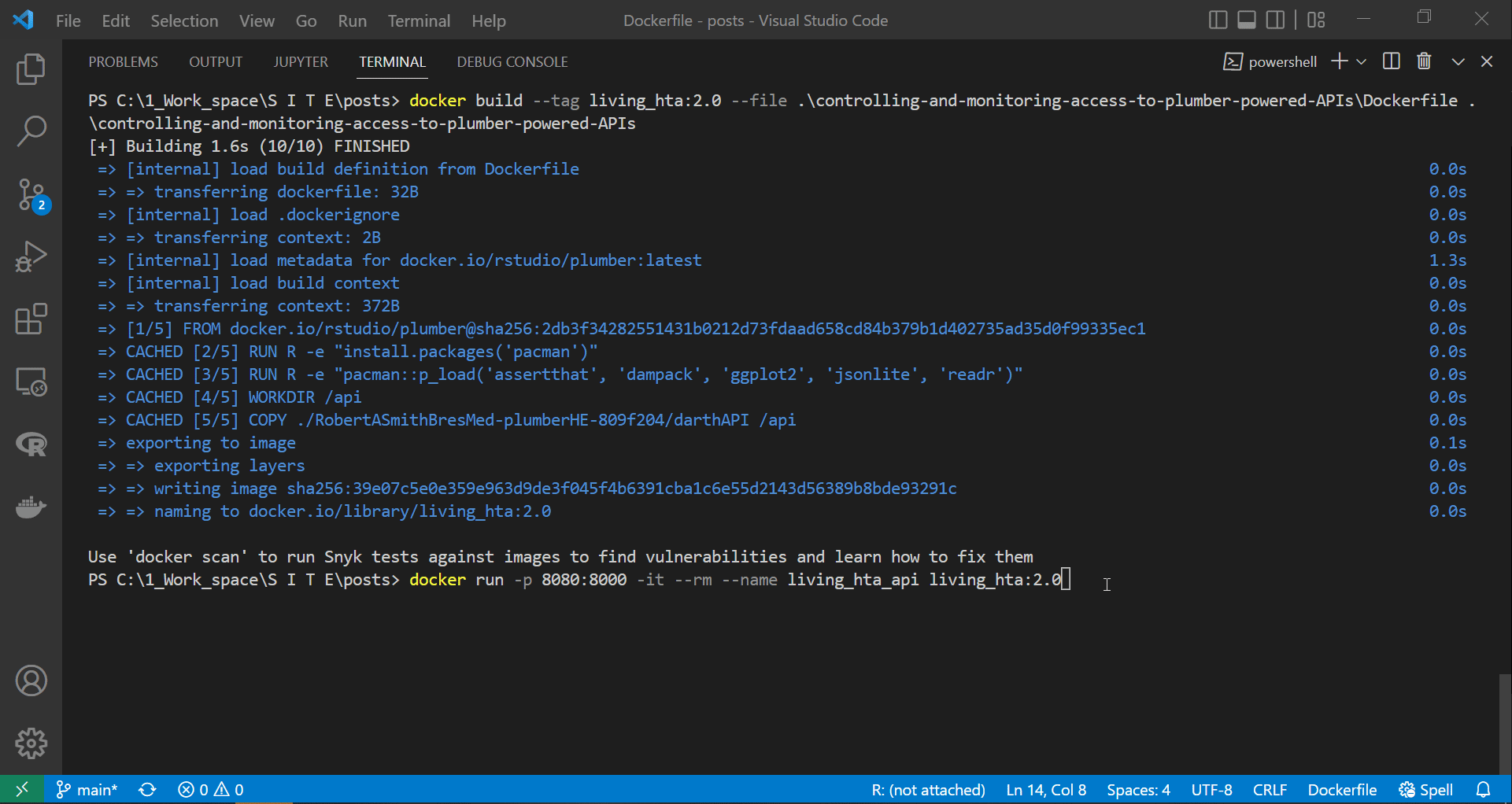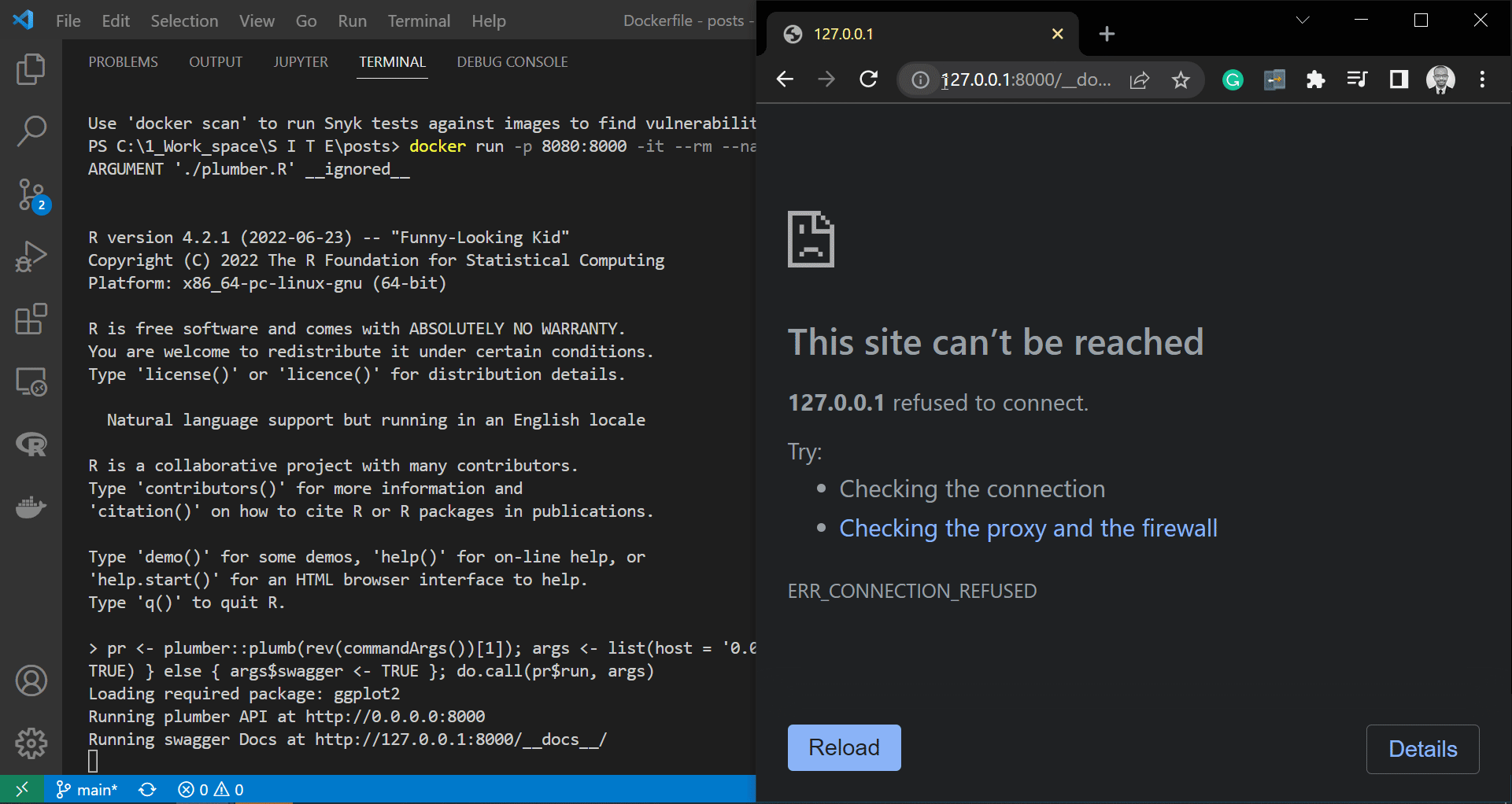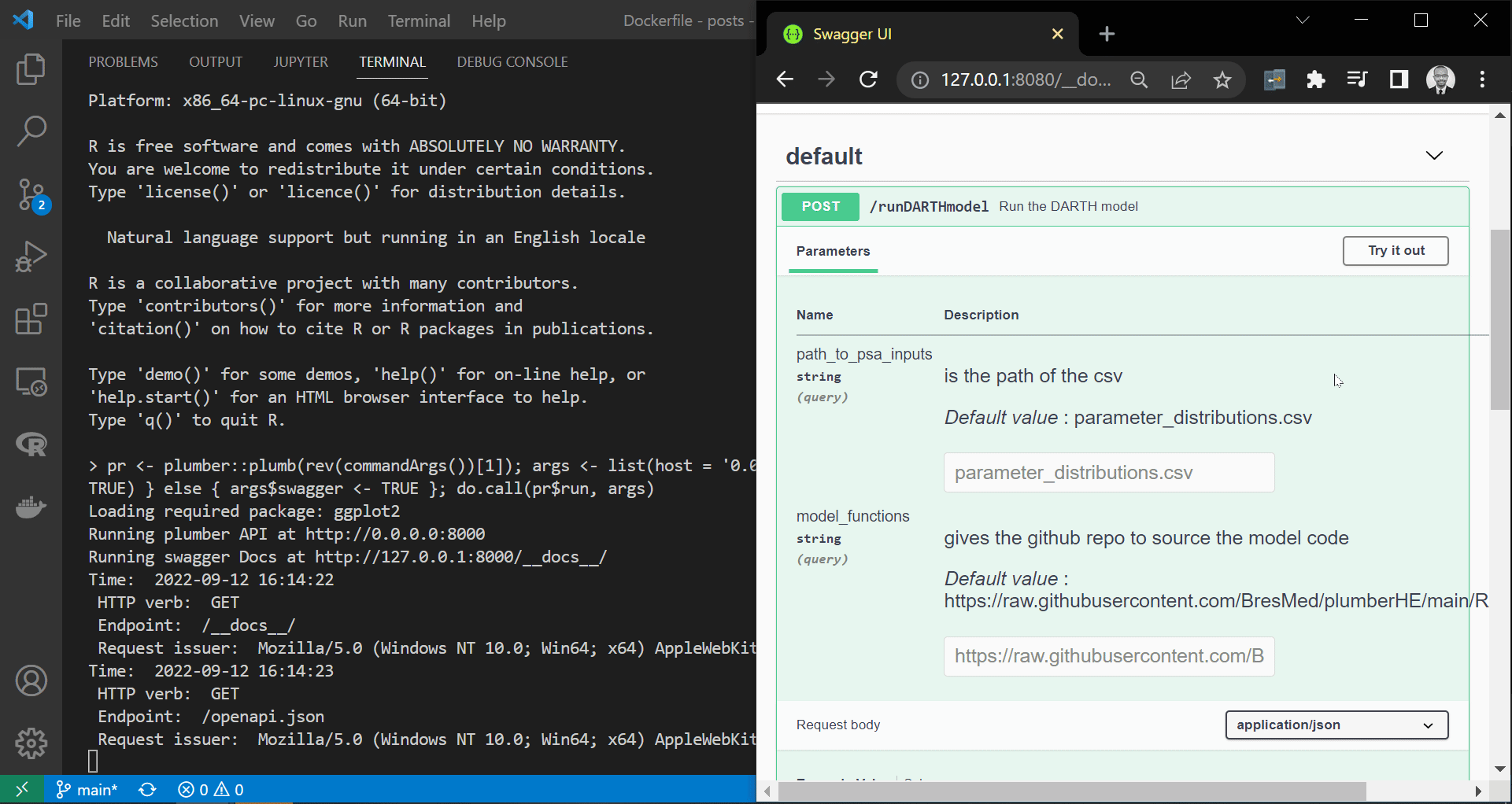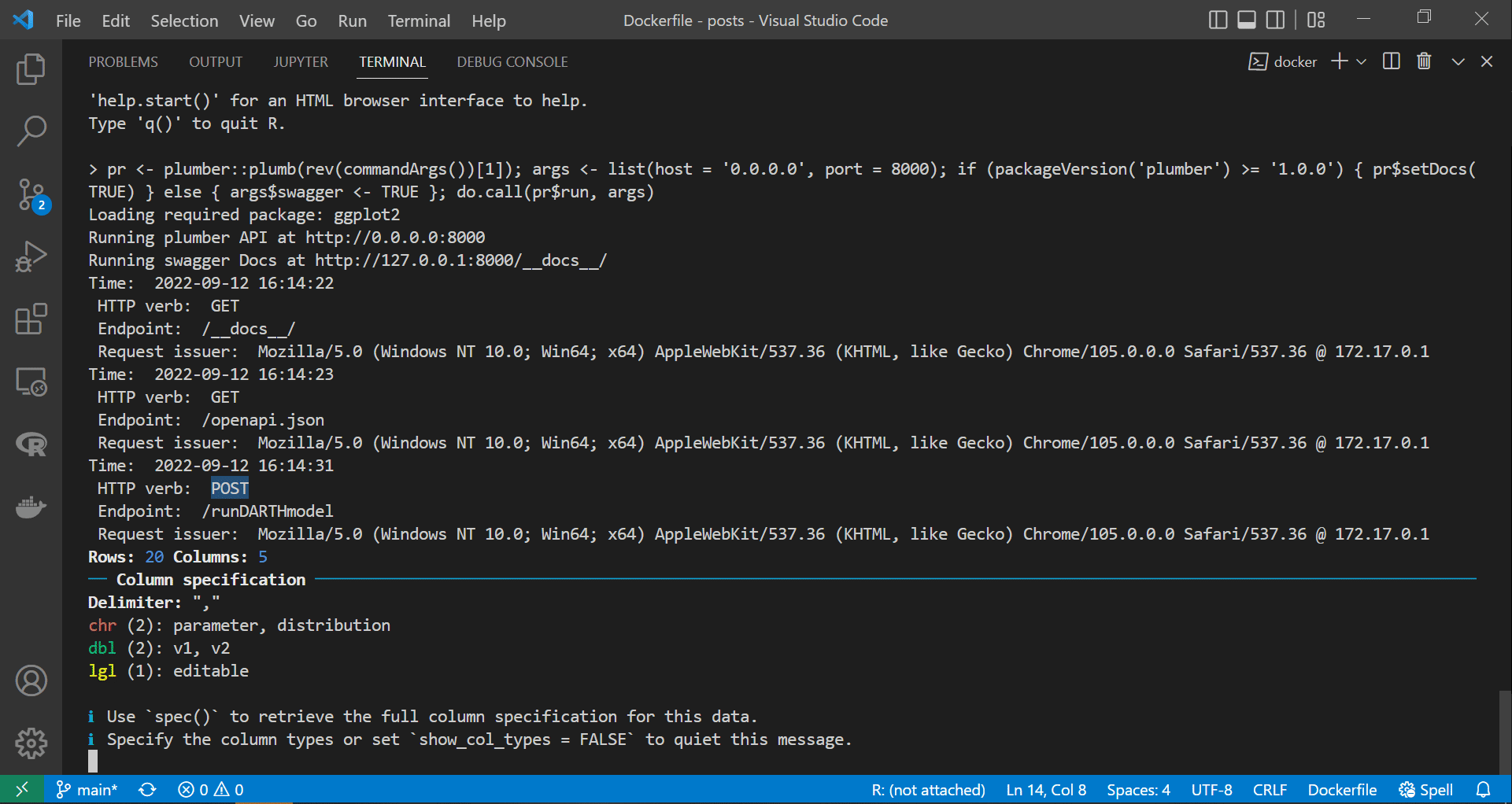 |
|---|
| The logger filter |
Controlling access to API endpoints:
Defining a security filter:
We can also use filters to control access to some or all API endpoints. Such filters make use of the request object and the information it packs. Let us dissect the code below to understand the use of filters to check users’ credentials.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#* Check user's credentials in the incoming request
#* @filter security
function(req, res, API_key = "R-HTA-220908") {
## Forward requests coming to swagger endpoints:
if (grepl("docs", tolower(req$PATH_INFO))
| grepl("openapi", tolower(req$PATH_INFO)))
return(plumber::forward())
## Check requests coming to other endpoints:
### Grab the key passed in the HEADERS list:
key <- NULL
if (!is.null(req$HEADERS['key'])) {
key <- req$HEADERS['key']
}
### Check the key passed through with the request object, if any:
if (is.null(key) | is.na(key)) {
#### Unauthorised users:
res$status <- 401 # Unauthorised
#### Log outcome:
cat(
"Authorisation status: 401. API key missing! \n"
)
return(list(error="Authentication required. Please add your API key to the HEADER object using the 'key' value and/or contact API administrator."))
} else {
#### Correct credentials:
if(key == API_key) {
#### Log outcome:
cat(
"Authorisation status: authorised - API key accepted! \n"
)
plumber::forward()
} else {
#### Incorrect credentials:
res$status <- 403 # Forbidden
#### Log outcome:
cat(
"Authorisation status: 403. API key incorrect! \n"
)
return(list(error="Authentication failed. Please make sure you have authorisation to access the API and/or contact API administrator."))
}
}
}
In the definition of the security filter above we:
- forward swagger related requests to the relevant endpoints by checking the endpoint name in the request object PATH_INFO,
- check user provided
key’s within the request object HEADERS, - reject user’s attempts to access API endpoints if they did not provide a
keyor provided the wrong one, and - forward requests with approved
key’s to the next handler in the pipeline.
 |
|---|
| Trying to access secured API endpoint |
In the gif file above, we demonstrate how adding the security filter alters access to the API. As we can see, accessing the /runDARTHmodel endpoint from the swagger page returns a 401 error and lets us know that we did not submit a key with the API request.
Interacting with secured API:
Passing credentials to the API:
So, how can we pass a key with our request? Even better, how can we programmatically provide our API credentials? To answer this question, we make use of the httr package, as we can see in the code chunk below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# remember to load a package that exports the pipe "%>%":
results <- httr::POST(
## the Server URL can also be kept confidential, but will leave here for now:
url = "http://127.0.0.1:8080",
## path for the API within the server URL:
path = "/runDARTHmodel",
## code is passed to the client API from GitHub:
query = list(model_functions =
paste0("https://raw.githubusercontent.com/",
"BresMed/plumberHE/main/R/darth_funcs.R")),
## set of parameters to be changed:
body = list(
param_updates = jsonlite::toJSON(
data.frame(parameter = c("p_HS1","p_S1H"),
distribution = c("beta","beta"),
v1 = c(25, 50),
v2 = c(150, 100)))),
## pass the API key to the request object:
config = httr::add_headers(
key = "R-HTA-220908")) %>%
httr::content()
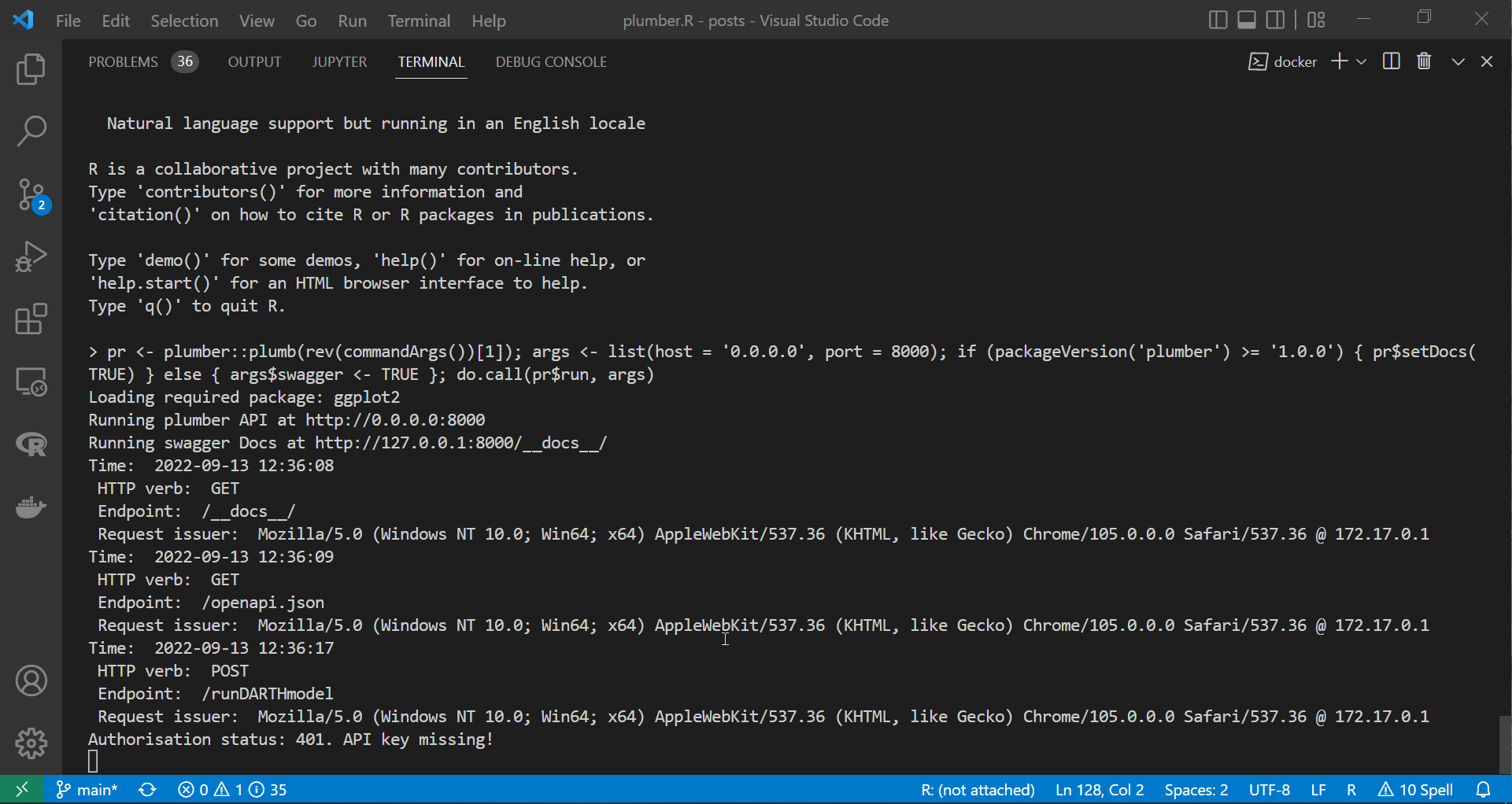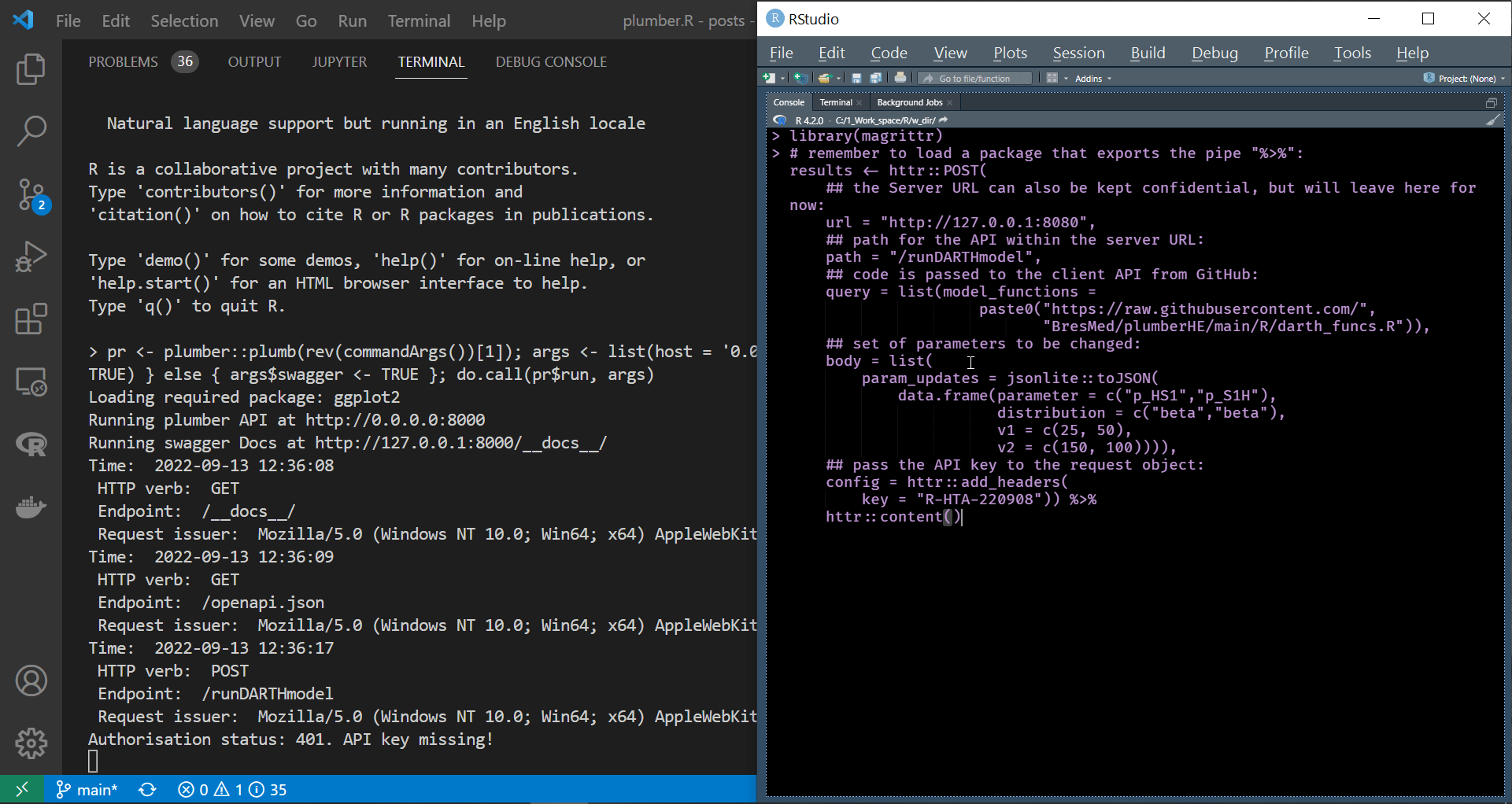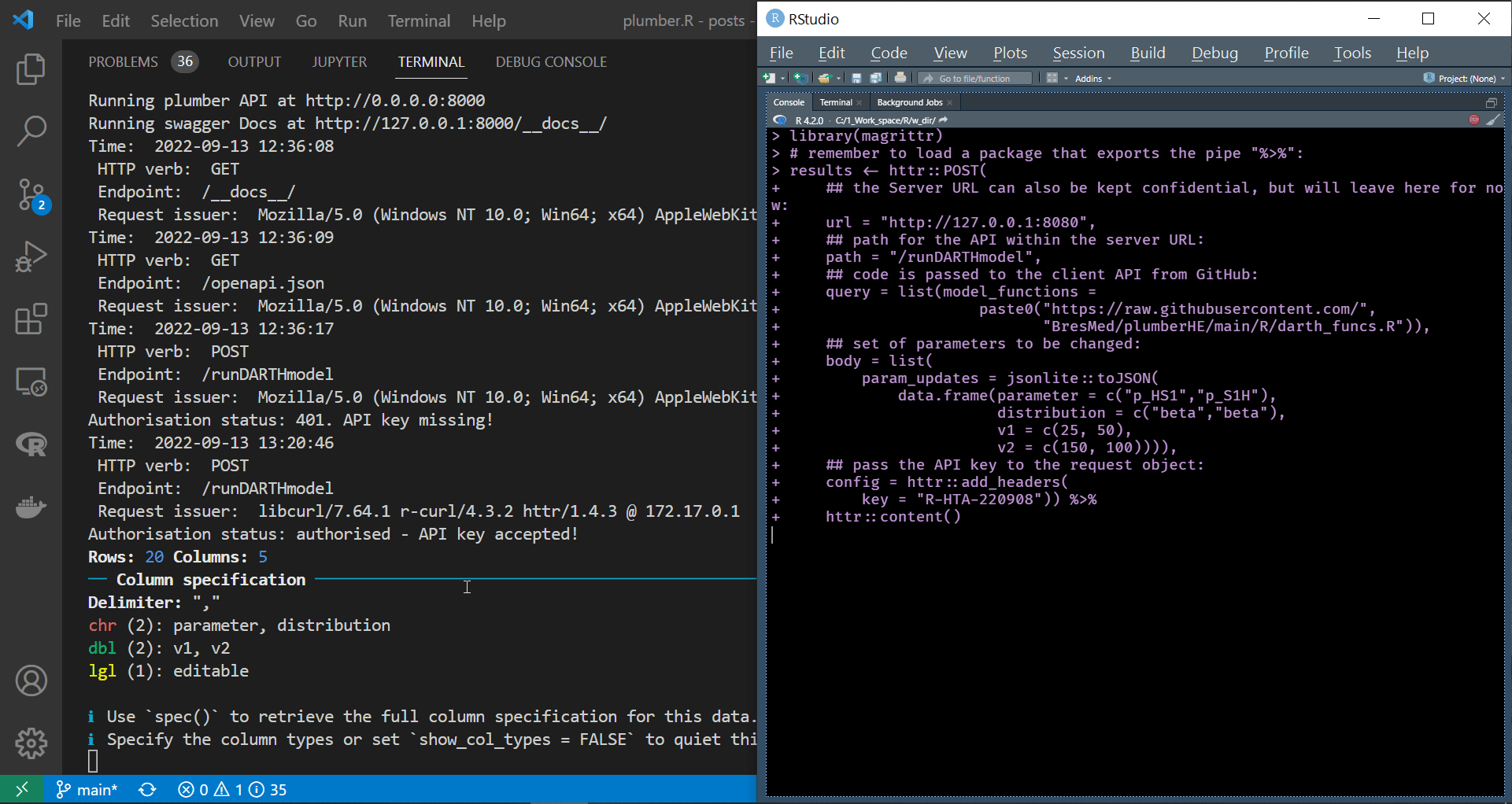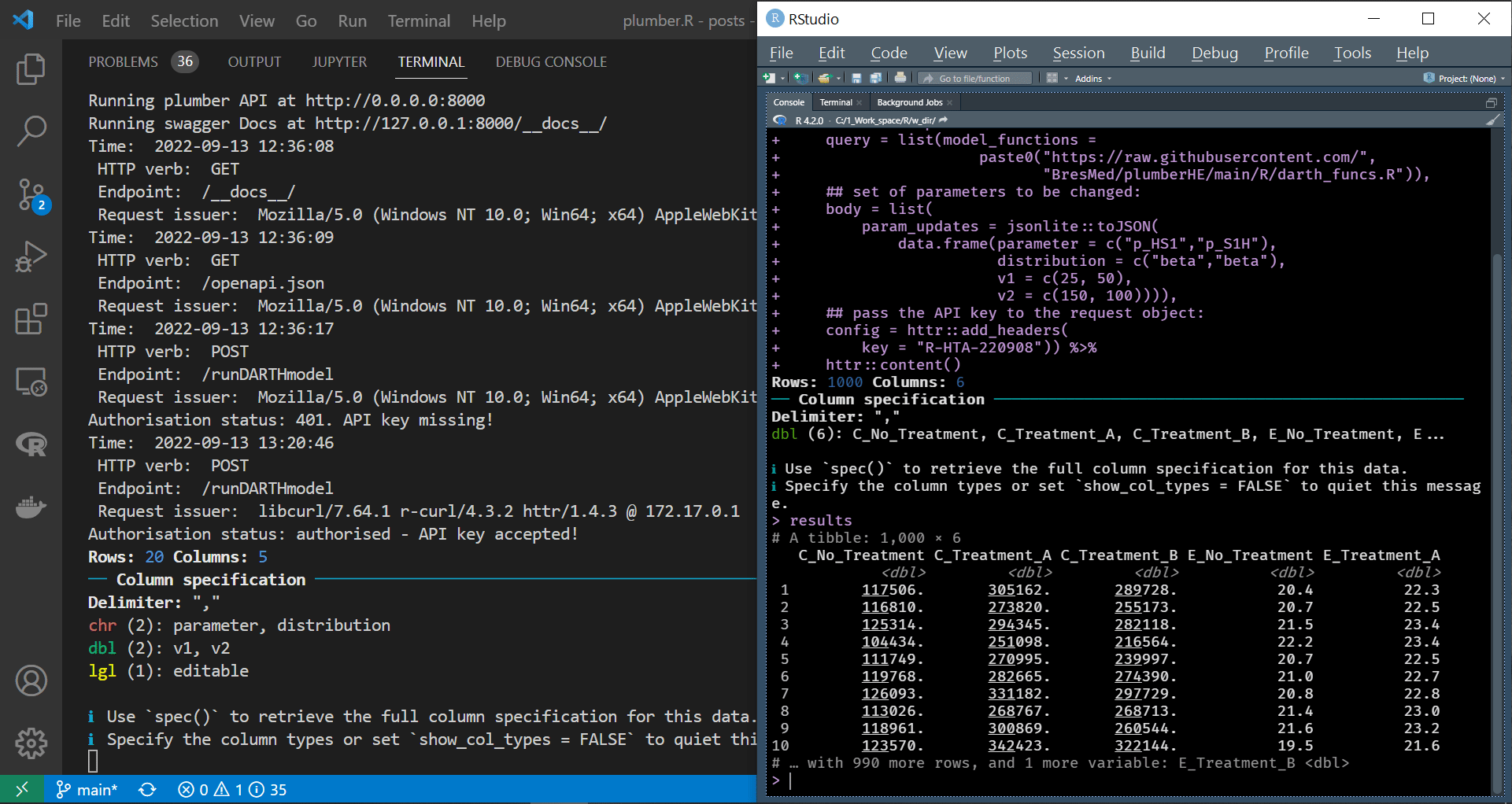
We have already discussed most of the relevant httr functions and arguments in a previous post. However, we have not covered the config argument and the httr::add_headers function, which we employ here to attach our credentials to the request body. Notice that the header’s name added, to the request body, by the httr::add_headers function can be whatever we want, and in this case, it is key. We display processing the code chunk above in an R session to interact securely with the API in the screen recording below.
 |
|---|
| Programmatically interacting with a secure API |
As we can see from the container’s terminal, the API has accepted the request and the key and printed “Authorisation status: authorised - API key accepted!” to the console before passing the request to the intended endpoints.
Exempting an endpoint from security checks:
We had slightly covered this point earlier when we forwarded swagger intended requests without checking for credentials. However, while we scripted that exemption manually, the plumber package provides a more seamless tool. In addition to the two filters we introduced earlier, we script a new endpoint to the Smith et al. (2022) API below. One unique addition to this new endpoint is the @preempt flag which allows us to name the filter from which we want the plumber to exempt the endpoint (i.e. plumber will pass requests to said endpoint without going through the named filter).
1
2
3
4
5
6
#* Scientific paper
#* @preempt security
#* @get /paper
function(){
return("https://wellcomeopenresearch.org/articles/7-194")
}
The gif file below shows how the requests to the newly added endpoint do not pass by the security filter.
 |
|---|
| Exempting an endpoint from an API security filter |
Code:
The dockerfile:
The dockerfile we used to build the API image.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Dockerfile
# Get the docker image provided by plumber developers:
FROM rstudio/plumber
# Install the R package `pacman`:
RUN R -e "install.packages('pacman')"
# Use pacman to install other required packages:
RUN R -e "pacman::p_load('assertthat', 'dampack', 'ggplot2', 'jsonlite', 'readr')"
# Create a working directory in the container:
WORKDIR /api
# Copy API files to the created working directory in the container:
COPY ./RobertASmithBresMed-plumberHE-809f204/darthAPI /api
# Specify the commands to run once the container runs:
CMD ["./plumber.R"]
The API script:
Below is an amended version of the file by Smith et al. (2022).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
#################
library(dampack)
library(readr)
library(assertthat)
#* @apiTitle Client API hosting sensitive data
#*
#* @apiDescription This API contains sensitive data, the client does not
#* want to share this data but does want a consultant to build a health
#* economic model using it, and wants that consultant to be able to run
#* the model for various inputs
#* (while holding certain inputs fixed and leaving them unknown).
#* Log some information about the incoming request
#* @filter logger
function(req) {
cat(
"Time: ", as.character(Sys.time()), "\n",
"HTTP verb: ", req$REQUEST_METHOD, "\n",
"Endpoint: ", req$PATH_INFO, "\n",
"Request issuer: ", req$HTTP_USER_AGENT, "@", req$REMOTE_ADDR, "\n"
)
plumber::forward()
}
#* Check user's credentials in the incoming request
#* @filter security
function(req, res, API_key = "R-HTA-220908") {
## Forward requests coming to swagger endpoints:
if (grepl("docs", tolower(req$PATH_INFO)) |
grepl("openapi", tolower(req$PATH_INFO))) {
return(plumber::forward())
}
## Check requests coming to other endpoints:
### Grab the key passed in the HEADERS list:
key <- NULL
if (!is.null(req$HEADERS["key"])) {
key <- req$HEADERS["key"]
}
### Check the key passed through with the request object, if any:
if (is.null(key) | is.na(key)) {
#### Unauthorised users:
res$status <- 401 # Unauthorised
#### Log outcome:
cat(
"Authorisation status: 401. API key missing! \n"
)
return(list(error = "Authentication required. Please add your API key to the HEADER object using the 'key' value and/or contact API administrator."))
} else {
#### Correct credentials:
if (key == API_key) {
#### Log outcome:
cat(
"Authorisation status: authorised - API key accepted! \n"
)
plumber::forward()
} else {
#### Incorrect credentials:
res$status <- 403 # Forbidden
#### Log outcome:
cat(
"Authorisation status: 403. API key incorrect! \n"
)
return(list(error = "Authentication failed. Please make sure you have authorisation to access the API and/or contact API administrator."))
}
}
}
#* Run the DARTH model
#* @serializer csv
#* @param path_to_psa_inputs is the path of the csv
#* @param model_functions gives the github repo to source the model code
#* @param param_updates gives the parameter updates to be run
#* @post /runDARTHmodel
function(path_to_psa_inputs = "parameter_distributions.csv",
model_functions = paste0("https://raw.githubusercontent.com/",
"BresMed/plumberHE/main/R/darth_funcs.R"),
param_updates = data.frame(
parameter = c("p_HS1", "p_S1H"),
distribution = c("beta", "beta"),
v1 = c(25, 50),
v2 = c(150, 70)
)) {
# source the model functions from the shared GitHub repo...
source(model_functions)
# read in the csv containing parameter inputs
psa_inputs <- as.data.frame(readr::read_csv(path_to_psa_inputs))
# for each row of the data-frame containing the variables to be changed...
for(n in 1:nrow(param_updates)){
# update parameters from API input
psa_inputs <- overwrite_parameter_value(
existing_df = psa_inputs,
parameter = param_updates[n,"parameter"],
distribution = param_updates[n,"distribution"],
v1 = param_updates[n,"v1"],
v2 = param_updates[n,"v2"])
}
# run the model using the single run-model function.
results <- run_model(psa_inputs)
# check that the model results being returned are the correct dimensions
# here we expect a single dataframe with 6 columns and 1000 rows
assertthat::assert_that(
all(dim(x = results) == c(1000, 6)),
class(results) == "data.frame",
msg = "Dimensions or type of data are incorrect,
please check the model code is correct or contact an administrator.
This has been logged"
)
# check that no data matching the sensitive csv data is included in the output
# searches through the results data-frame for any of the parameter names,
# if any exist they will flag a TRUE, therefore we assert that all = F
assertthat::assert_that(all(psa_inputs[, 1] %in%
as.character(unlist(x = results,
recursive = T)) == F))
return(results)
}
#* Scientific paper
#* @preempt security
#* @get /paper
function(){
return("https://wellcomeopenresearch.org/articles/7-194")
}
Conclusion:
This short tutorial introduced plumber filters and discussed their role as security handlers. However, there is more to APIs security than we discussed in this post. Therefore, we strongly advise readers to read through the plumber’s Security page to get a more comprehensive picture on API’s security.